Fine-Tuning | Quantize | Infer — Qwen2-VL mLLM on Custom Data for OCR: Part 1
Custom Dataset Preparation

This is the 1st part of my three-part series about fine-tuning and quantizing the Qwen2-VL model on a custom dataset for OCR.
Recently, I fine-tuned Qwen2-VL-2B, which is a multimodal LLM, meaning it can analyze both text and images. I aimed to extract the required information (OCR) from images using this model. This blog will cover everything from how I created my image dataset (labeling and formatting), trained the model, quantized it, and evaluated the model.
In this part, I have focused solely on preparing a custom dataset for fine-tuning the Qwen2-VL model.
Blog Series:
- Custom Dataset Preparation for multimodel LLM fine-tuning(Qwen2-VL) (This Blog)
- LoRA Fine-Tuning Qwen2-VL
- Quantization and Inferencing of custom Qwen2-VL-2B mLLM (GPTQ and AWQ)
Why did I choose Qwen2-VL for this task over other OCR models?
Many articles cover the in-depth workings of Qwen2-VL, so I do not intend to include those details here. I chose Qwen2-VL for OCR mainly because of its enhanced image comprehension capabilities (including video understanding) and its parameter size of 2B (7B and 72B are also available), which supports the Nvidia GPU that I intend to use in production (more on this later). Additionally, the benchmark numbers are impressive compared to other multimodel LLMs.

Check out the following blog to know more about Qwen2-VL.
https://qwenlm.github.io/blog/qwen2-vl
I also fine-tuned PaddleOCR-v4 on this dataset. After comparing the results of the fine-tuned models from both PaddleOCR-v4 and Qwen2-VL, I concluded that the LLM-based approach achieves higher accuracy for my use case.
I also have compared the results of our Qwen2-VL-2B model with Azure Document Intelligence OCR and I must say the results are almost equal if not better.
However, I want to finetune stepfun-ai/GOT-OCR2_0 and compare the results with Qwen2-VL. Will do it later.
Custom Dataset Preparation
There are few resources available on creating custom training datasets specifically for LLM training using one’s own data. After spending considerable time navigating this process, I decided to provide a comprehensive, in-depth guide in this blog.
I am mainly using Linux for fine-tuning, quantization, and inference of the model, as stable Windows support is not available yet. However, I will update this blog if I successfully build it on Windows.
I started by collecting images (around 3,000) and labeling them. My main objective is to extract the Model, Vehicle Sr. No., and Engine No. from the VIN plate images and the Chassis No. from the chassis images.
Here are sample images and their OCR label format.
Vinplate Image:

“vinplate.jpg”:
{
"Vehicle Sr No": "MA1TA2YS2R2A13882",
"Engine No": "YSR4A38798",
"Model": "SCORPIO CLASSIC S5 MT 7S"
}Chassis Image:

"chassis.jpg":
{
"Vehicle Sr No": "MA1TA2YS2R2A17264",
"Engine No": null,
"Model": null
}Finally, after combining all the labels, the final JSON file will look something like this :
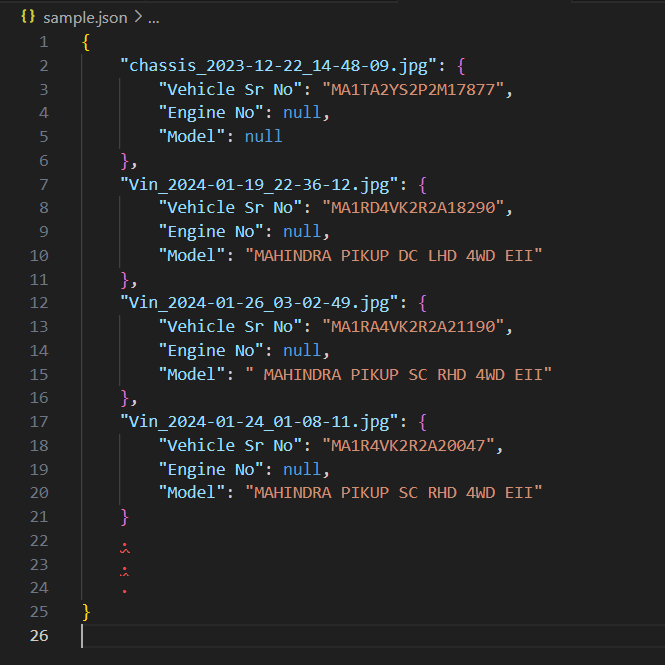
Let’s name this JSON file combined-ocr-json.json.
This is NOT exactly the format required for fine-tuning the Qwen2-VL model. We still need to convert it into the format that Qwen2-VL requires. I used Llama-Factory for dataset preparation and model fine-tuning. The required format is mentioned in the repository here, and we need to create a similar format.
The input format for a single image data entry in our model will look like this:
{
"messages": [
{
"content": "<image>Can you find and provide the Vehicle Sr No, Engine No, and Model from the image?",
"role": "user"
},
{
"content": "{\n \"Vehicle Sr No\": \"MA1TA2YS2R2A13882\",\n \"Engine No\": YSR4A38798,\n \"Model\": SCORPIO CLASSIC S5 MT 7S\n}",
"role": "assistant"
}
],
"images": [
"path/to/imagefolder/vinplate.jpg"
]
}Here, the ‘messages’ key contains the main user query and corresponding LLM output, and the ‘images’ key contains the list of the image paths. In my case, only one image is passed per query. If there are multiple images per query, then need to add corresponding numbers of tags in the ‘content’.
For example for 2 images,
{
"messages": [
{
"content": "<image><image>Can you find and provide the Vehicle Sr No, Engine No, and Model from the image?",
"role": "user"
},
{
"content": "{\n \"Vehicle Sr No\": \"MA1TA2YS2R2A13882\",\n \"Engine No\": YSR4A38798,\n \"Model\": SCORPIO CLASSIC S5 MT 7S\n},
{\n \"Vehicle Sr No\": \"MA1TA2YS2R2A13883\",\n \"Engine No\": YSR4A38799,\n \"Model\": SCORPIO CLASSIC S5 MT 7S\n}",
"role": "assistant"
}
],
"images": [
"path/to/imagefolder/vinplate1.jpg",
"path/to/imagefolder/vinplate2.jpg",
]
}and so on.
Now, to convert our label format to the required format, I have created the following Python code.
import json
import random
def generate_user_query():
variations = [
"Extract out the Vehicle Sr No, Engine No, and Model from the given image.",
"Can you provide the Vehicle Sr No, Engine No, and Model for this image?",
"What is the Vehicle Sr No, Engine No, and Model in the given image?",
"Please extract the Vehicle Sr No, Engine No, and Model from this image.",
"Find the Vehicle Sr No, Engine No, and Model in this image.",
"Retrieve the Vehicle Sr No, Engine No, and Model from the image provided.",
"What are the Vehicle Sr No, Engine No, and Model present in this image?",
"Identify the Vehicle Sr No, Engine No, and Model from this image.",
"Could you extract the Vehicle Sr No, Engine No, and Model from the attached image?",
"Provide the Vehicle Sr No, Engine No, and Model from the image.",
"Please determine the Vehicle Sr No, Engine No, and Model for this image.",
"Extract the information for Vehicle Sr No, Engine No, and Model from the given image.",
"What is the Vehicle Sr No, Engine No, and Model information extracted from this image?",
"Can you pull the Vehicle Sr No, Engine No, and Model from the image?",
"Retrieve the Vehicle Sr No, Engine No, and Model details from this image.",
"Get the Vehicle Sr No, Engine No, and Model from the provided image.",
"Please extract and provide the Vehicle Sr No, Engine No, and Model for this image.",
"What Vehicle Sr No, Engine No, and Model can be identified in the image?",
"I need the Vehicle Sr No, Engine No, and Model from this image.",
"Can you find and provide the Vehicle Sr No, Engine No, and Model from the image?"
]
return random.choice(variations)
def convert_to_format(input_data, image_folder_path):
formatted_data = []
for image_name, details in input_data.items():
user_query = generate_user_query()
formatted_entry = {
"messages": [
{
"content": '<image>'+user_query,
"role": "user"
},
{
"content": json.dumps(details, indent=4),
"role": "assistant"
}
],
"images": [
f"{image_folder_path}/{image_name}"
]
}
formatted_data.append(formatted_entry)
return formatted_data
def load_input_json(input_json_path):
with open(input_json_path, 'r') as json_file:
input_data = json.load(json_file)
return input_data
def main(input_json_path, image_folder_path, output_json_path):
input_data = load_input_json(input_json_path)
formatted_output = convert_to_format(input_data, image_folder_path)
with open(output_json_path, 'w') as json_file:
json.dump(formatted_output, json_file, indent=4)
print(f"Formatted output saved to {output_json_path}")
input_json_path = 'combined-ocr-json.json'
image_folder_path = 'path/to/imagefolder' # Folder where images are stored
output_json_path = 'final-llm-input.json' # Path for the output JSON file
main(input_json_path, image_folder_path, output_json_path)Here is what the combined JSON file will look like. It will contain the list of JSONs. The filename will be final-llm-input.json
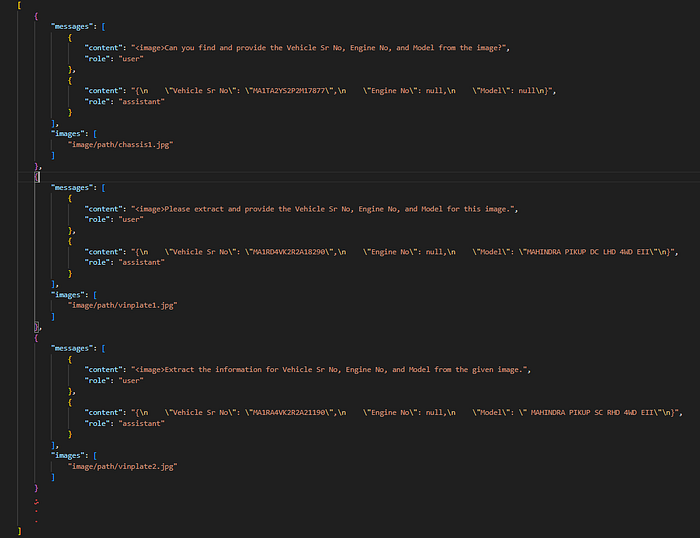
Notice how the content differs in each sample; this is important for providing variation in user queries.
This is the main JSON file that will be used to fine-tune the Qwen2-VL model.
Note: You can create this JSON file directly without following the intermediate steps; I just want to explain how I created the dataset for fine-tuning.
In the next part, we will begin fine-tuning the model.
Follow me on LinkedIn: https://www.linkedin.com/in/bhavyajoshi809
